Deep Learning Theory
Introduction
- Why deep learning?
- conventional machine learning methods can not utilize the power of big data
- their performance saturates after a certain number of data
- Why sudden boom?
- lots of data
- computational power
- new algorithms for fast optimization
- Types of data
- structured - housing prices, financial
- unstructured - Images, Audio, Speech, Text (deep learning very strong here)
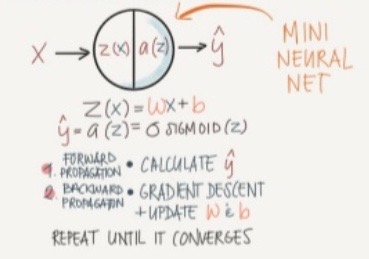
- Logistic regression
- classification algorithm
-
2 steps:
step 1: forward propagation
- data : (x,y)
- compute z = w1x1+w2x2+b
- compute a = sigmoid(z)
- compute loss = L(a,y)
- compute cost J(w) = average loss calculated over all training samples
step 2: backward propagation
- compute gradient of loss/cost wrt to weights : dL/dw = dL/da * dL/dz * dz/dw
- update weights using gradient descent: w := w - alpha*dL/dw
Then, compute forward propagation again and repeat the process
- Loss function
- measures how good is our classifier by comparing the predicted value with the true value
- we minimize the loss function to achieve the best parameters for the classifier
- minimization of loss function (or cost function) is done using gradient descent
- common loss functions are:
- mean squared error : does not work well in logistic regression (?)
- cross-entropy : -log(likelihood) - cost function is summation of loss over all the training samples
- Gradient descent
- Maximum likelihood estimation
- Perceptron
. Shallow Neural Network
- series of logistic regression units
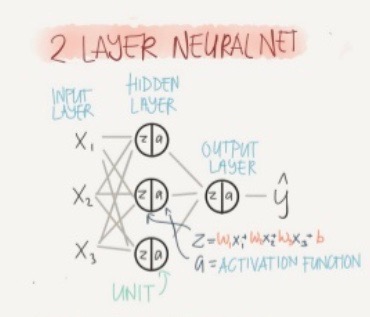
-
Activation functions
- Sigmoid - binary classification, output layer
- Tanh - normalized sigmoid, centers the data to avoid extremes which improves learning
- Relu - removes negative activations, hidden layer, removes vanishing gradient
- Leaky relu - to avoid undefined slope at (0,0)
- with no activation a = z, so no non-linearity is learnt by the network. Thus, the whole neural network simply becomes linear regression
- Initialization of weights
- if all weights are intialized to zero, all activations are same, all nodes have same effect on output, all weights are updated by same amount. All units learn exactly the same features - no new learning
- to break this symmetry, weights are initialized randomly
- also, weights should be small to prevent extreme values of activation which cause vanishing gradient
- Deep neural network
- learn more complex features than shallow networks
- require lot of data and computation power