Machine Learning and Deep Learning
Important Articles
- Machine learning glossary by Google
- Essentials of Machine Learning Algorithms
- Deep learning course summary by analytics vidya
- Cheatsheet – Python & R codes for common Machine Learning Algorithms
- Troubleshooting Deep Neural Networks by Josh Tobin
Topics
-
Cross-validation
-
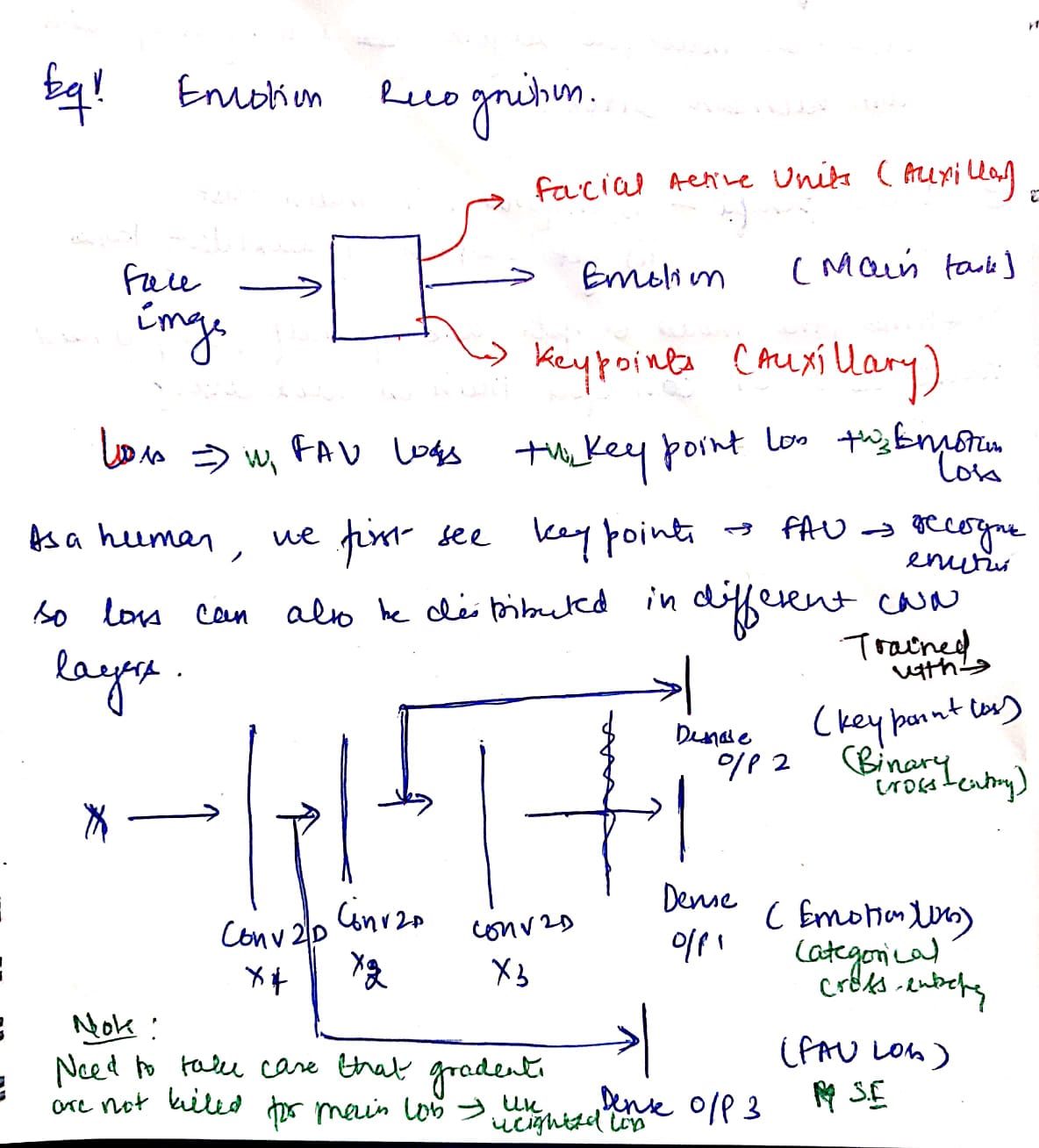
Multi-task Learning
- a kind of regularization or conditioning with auxillary tasks. Reduced model complexity by adding additional priors which reduces overfitting.
- dual benefits- improvement in main task and additional outputs from auxillary tasks
- can train the model with multiple losses and weigh each loss as per our requirement. Also we can distribute the losses at multiple layers taking inspiration from human cortex.
-
can help the model focus its attention on those features that actually matter as other tasks will provide additional evidence for the relevance or irrelevance of those features.
-
Why does different close tasks help to learn the main task or why they can learn jointly together?
-
Regularization - additional loss adds regularization, smoothes the loss function, minimize the complexity of model and gives very informative priors to the model.
-
Representation Bias - when you train a model over an intersection of several tasks, you push your learning algorithm to find a solution on a smaller area of representation on the intersection rather than on a large area of a single task. It leads to better and faster convergence.
-
Feature Selection Double Check - if one feature is importnat for more than just one task, then most probably this feature is indeed very important and representative of your data.
-
O/Ps that can't be inputs - certain past observations have an influence on future observations, so we can use them as auxillary loss functions to regularize our model for ‘knowing about them. Same goes with features that are too difficult to calculate in testing phase but we can add them as extra info in our model.
-
Transfer Learning - instead of first learning one task and then using the same model to learn another task over it, we jointly learn the tasks and has shown better performance.
-
References:
- An Overview of Multi-Task Learning in Deep Neural Networks
- Multitask learning: teach your AI more to make it better
- Why deep learning?
-
conventional machine learning methods can not utilize the power of big data
- Why sudden boom?
- lots of data
- computational power
-
new algorithms for fast optimization
- types of data
- structured
-
unstructured (deep learning very strong here)
- Logistic regression
- classification algorithm
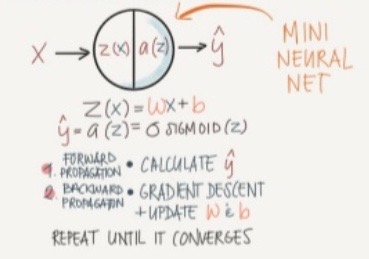
- steps:
forward propagation
- data : (x,y)
- compute z = w1x1+w2x2+b
- compute a = sigmoid(z)
- compute loss = L(a,y)
- compute cost J(w) = average loss calculated over all training samples
backward propagation
- compute gradient of loss/cost wrt to weights : dL/dw = dL/da * dL/dz * dz/dw
- update weights using gradient descent: w := w - alpha*dL/dw
compute forward propagation again
- loss function
- mean squared error : does not work well in logistic regression (?)
-
cross-entropy : -log(likelihood)
- Shallow Neural Network
-
series of logistic regression units
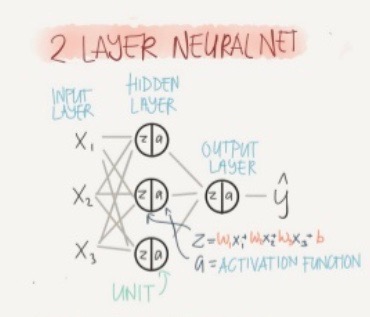
- Activation functions
- Sigmoid - binary classification, output layer
- Tanh - normalized sigmoid, centers the data to avoid extremes which improves learning
- Relu - removes negative activations, hidden layer, removes vanishing gradient
- Leaky relu - to avoid undefined slope at (0,0)
-
with no activation a = z, so no non-linearity is learnt by the network. Thus, the whole neural network simply becomes linear regression
- Initialization of weights
- if all weights are intialized to zero, all activations are same, all nodes have same effect on output, all weights are updated by same amount. Al units learn exactly the same features - no new learning
- to break this symmetry, weights are initialized randomly
-
also, weights should be small to prevent extreme values of activation which cause vanishing gradient
- Deep neural network
- learn more complex features than shallow networks
- require lot of data and computation power